Vejledning til deklaration af datasæt med kernedimensioner
Introduktion
Denne vejledning til deklaration af datasæt med kernedimensioner beskriver en metode til at angive oplysninger om datakvalitet i et givet udstillet datasæt med det formål at lette dialog mellem den dataansvarlige organisation og eksterne anvendere af datasættet og gøre det lettere at vurdere om et datasæt er egnet til en givet (ny) anvendelse. Metoden er udviklet til brug i dansk fællesoffentlig sammenhæng på baggrund af internationale standarder, nemlig W3Cs Data on the Web Best Practices: Data Quality Vocabulary[1](#fodnote 1) og ISO 25012 – Data Quality Model[2](#fodnote 2).
ISO 25012 definerer datakvalitet som ”grad af tilfredsstillelse af udtrykte og underforståede behov datas egenskaber giver ved brug under specifikke omstændigheder”[3](#fodnote 3). Selvom der findes mange andre definitioner af datakvalitet, er der i disse gennemgående et fokus på datas egnethed i en bestemt brugssituation – ’fitness for use’. Baggrunden for dette er at data der er velegnede til et formål, og derfor vil blive anset som værende af høj kvalitet af anvendere der bruger dem til dette formål, kan være uegnet til et andet formål, hvorfor andre anvendere vil anse de samme data for at være af lav kvalitet.
Ikke desto mindre kan det i forbindelse med deling og udstilling af datasæt være relevant at tale om datakvalitet uden at kende den eller de helt præcise anvendelser eksterne anvendere bruger eller vil bruge data til. Her må den dataansvarlige, ud fra sit kendskab til data og det faglige domæne de tilhører, vurdere hvad det især er sandsynligt at eksterne anvendere allerede anvender eller vil ønske at anvende data til. Dette vil herefter benævnes de væsentligste forventede anvendelser.
Scope
Den metode til beskrivelse ad datakvalitet der er beskrevet i denne vejledning, og de deklarationer der resulterer fra den, er først og fremmest beregnet til at facilitere dialog mellem den dataansvarlige organisation og (potentielle) dataanvendere ved at anvise et fælles, entydigt sprog om datakvalitet.
Den er ikke beregnet til at være en metode til forbedring af datakvalitet, da metoder til dette varierer i forhold til datas karakter, men deklarationerne og den dialog med anvendere der resulterer heraf kan være et redskab til at identificere hvilke forbedringsindsatser der er behov for.
Ligeledes er metoden ikke beregnet til i sig selv at afgøre hvordan data kan anvendes i den offentlige forvaltning, da der i denne vurdering indgår juridiske og forvaltningsmæssige aspekter som ikke behandles her. Deklarationerne baseret på denne metode forventes dog at kunne indgå som input til en sådan vurdering.
Metoden er primært beregnet til deklaration af udstillede datasæt, hvor vurderingen af datakvalitet netop foretages i forhold til de væsentligste forventede anvendelser, og hvor deklarationen med fordel kan indgå som en del af den metadata der udstilles sammen med datasættet. Den forventes dog også at kunne anvendes til vurdering af data i forhold til en specifik beskrevet anvendelse, fx som svar på forespørgsel fra en kommende anvender. Metoden som helhed er beregnet til beskrivelse og bedømmelse af datasæt, hvor datasæt skal forstås som ”en samling af data, udstillet eller forvaltet af en enkelt aktør.”[4](#fodnote 4)
I forhold til behov for yderligere beskrivelse af datakvalitet som denne vejledning ikke dækker, samt maskinlæsbar angivelse af kvalitetsinformation, henvises til W3Cs Data on the Web Best Practices: Data Quality Vocabulary. Dansk oversættelse heraf samt vejledning til brug heraf med metrikkatalog er under udarbejdelse.
Metode til beskrivelse af datakvalitet
Datakvalitet kan beskrives i forhold til mange forskellige dimensioner som repræsenterer kriterier der er relevante for at vurdere datakvalitet. Hver dimension har tilknyttet en eller (oftest) flere standardiserede normer for hvordan man måler/beskriver datakvalitet i forhold til dimensionen.
Med baggrund i ISO 25012 og Linked Data Quality Dimensions (de to sæt af datakvalitetsdimensioner, der er gengivet i W3Cs Data Quality Vocabulary)[5](#fodnote 5) er der udvalgt fire kvalitetsdimensioner, her kaldet ’kernedimensioner’, der anses for at være særligt væsentlige i forhold til at vurdere om det er muligt at anvende datasæt til nye formål:
| Datakvalitetsdimension | Definition |
|---|---|
| Komplethed | datakvalitetsdimension der indikerer i hvor høj grad datasættet indeholder de dataelementer der er forventede i forhold til datasættets specifikation |
| Korrekthed | datakvalitetsdimension der indikerer i hvor høj grad dataværdier er i overensstemmelse med faktiske værdier |
| Aktualitet | datakvalitetsdimension der indikerer i hvor høj grad data er tidsmæssigt aktuelle i forhold til den virkelighed de repræsenterer |
| Genbrugelighed | datakvalitetsdimension der indikerer i hvor høj grad data er forståelige og uden vanskeligheder kan anvendes af andre |
Disse dimensioner er valgt fordi de vurderes at have bred relevans i forbindelse med udveksling af data for (stort set) alle typer af data og anvendelser, hvilket ses af at dimensioner med dette indhold er gennemgående litteratur om datakvalitet. Desuden anses det for væsentligt at de er iboende egenskaber for datasættet der vil være gældende for alle distributioner af datasættet, uanset hvordan det tilgås. Den dataansvarlige kan beskrive datasættet i henhold til disse dimensioner uden at indhente oplysninger fra anvendere om deres holdning til datasættet[6](#fodnote 6).
Det er anset for nødvendigt at begrænse antallet af dimensioner i forhold til de anvendte internationale standarder for at det ikke skal blive for stor en byrde at deklarere et datasæt med datakvalitetsoplysninger. Der findes et betydeligt antal yderligere dimensioner der kan være relevante for et givet datasæt eller en givet anvendelse, fx præcision, troværdighed eller tilgængelighed. I så tilfælde kan man anvende dimensioner ISO 25012 eller Linked Data Quality Dimension (oversigt ses i bilag D).
I bilag A findes Skabelon til angivelse af datakvalitet. På skabelonen angives navnet på datasættet, det formål det oprindeligt er indsamlet til, hvilken myndighed eller enhed der er ansvarlig for vurderingen samt dato for vurderingen. Desuden angives den/de væsentligste forventede anvendelser som datasættet er vurderet i forhold til.
Den/de væsentligste forventede anvendelser kan være anvendelser man ved andre eksterne parter bruger det til eller planlægger at bruge det til, mulige anvendelser der er begrundelsen for publicering af datasættet, eller anvendelser som dataansvarlig ud fra sit kendskab til domænet ved kunne være værdiskabende anvendelser af data. Som nævnt er datakvalitet afhængigt af det formål data skal anvendes til.
Det er vigtigt som minimum at angive én forventet anvendelse, så den potentielle dataanvender kan afgøre i hvor høj grad den/de anvendelser der har dannet grundlag for deklareringen svarer overens med vedkommendes planlagte anvendelse.
Skabelonen har to felter for hver kvalitetsdimension: Målinger og beskrivelser og Bedømmelse.
I Målinger og beskrivelser angives objektive oplysninger der beskriver datasættet i forhold til den relevante dimension. Det er intentionen at deklarationen skal kunne foretages på baggrund af den viden den dataansvarlige allerede har om datasættet. Derfor kan både være tale om resultater af konkrete målinger og (stikprøve)kontroller samt skøn, beregninger og tekstuelle beskrivelser. Det bør altid fremgå tydeligt om der er tale om en måling af hele datasættet, en stikprøvekontrol eller et skøn. I det følgende kapitel er der for hver dimension angivet hvilke målinger og beskrivelser, der er relevante for den dimension, og i skabelonen er der angivet hjælpespørgsmål, der kan fungere som hints for hvordan man beskriver hver dimension.
I Bedømmelse angives den dataansvarliges faglige vurdering af hvor god datasættets kvalitet er i forhold til den relevante dimension når det vurderes i forhold til den/de væsentligste anvendelser. Her skal den dataansvarlige i videst muligt omfang forsøge at sætte sig i dataanvenders sted og anslå hvor god datakvaliteten er fra dennes synspunkt.
Tildelingen af stjerner foretages på baggrund af oplysningerne i Målinger og beskrivelser. Denne udgør dermed begrundelsen for antallet af stjerner, der dog må anses som værende den dataansvarliges subjektive bedømmelse, og dermed er det muligt for anvendere at være uenige heri, og denne uenighed kan danne udgangspunkt for en dialog.
Bedømmelsesskala
Datasættet gives mellem 0 og 5 stjerner for hver dimension. Hvis forskellige forventede anvendelser giver anledning til forskelligt antal stjerner kan dette anføres i skabelonen eller der kan udarbejdes to separate deklarationer.
| Bedømmelse | Beskrivelse |
|---|---|
| ☆☆☆☆☆ | Bedømmes uegnet til den givne anvendelse |
| ★☆☆☆☆ | Bedømmes til dårligt at kunne anvendes |
| ★★☆☆☆ | Kan anvendes med forbehold for et større antal fejl/utilsigtede resultater |
| ★★★☆☆ | Kan anvendes med forbehold for fejl/utilsigtede resultater |
| ★★★★☆ | Kan anvendes med forbehold for enkelte fejl/utilsigtede resultater |
| ★★★★★ | Kan anvendes umiddelbart og uden forbehold |
Vurderingen kan til dels bero på hvor kritiske eventuelle fejl og mangler er i forhold datasættets formål og forventede anvendelser. Det vil for eksempel til de fleste anvendelser være væsentligt mere kritisk hvis et adresseregister mangler oplysninger om postnumre end hvis det mangler oplysninger om det præcise tidspunkt på dagen hvor en flytning er registreret, hvorimod det i et datasæt om meteorologiske observationer kan være mere kritisk hvis tidspunktet for observationen mangler, og man kan formode at tidspunktet skal være mere nøjagtigt angivet, og datasættet væsentligt oftere opdateret, hvis de meteorologiske observationer skal kunne anvendes til vejrudsigt end hvis de skal anvendes til klimaforskning.
Ved eventuel vurdering af et datasæt i forhold til en specifik anvendelse, fx på baggrund af en forespørgsel fra en potentiel kommende anvender tages hensyn til de krav denne dataanvender har specificeret.
Eksempel på bedømmelse
Et datasæt bestående af målingsresultater vil have en meget høj aktualitet, hvis resultater af målinger med det samme registreres i det tilgængelige datasæt. Til nogle anvendelser vil aktualitet stadig kunne betragtes som god selv om der går længere tid inden målingerne registreres og publiceres.
Er der fx tale om et datasæt bestående af meteorologiske målinger, hvor den væsentligste forventede anvendelse er planlægning af luft- og skibsfart, vil målingerne hurtigt blive irrelevante. En opdateringsfrekvens på 6 måneder må bedømmes til 0 stjerner.
Er den væsentligste forventede anvendelse derimod klimaforskning må en opdateringsfrekvens på 6 måneder forventes at være glimrende og datasættet kunne gives 5 stjerner for aktualitet.
Hvis både planlægning af luft- og skibsfart og klimaforskning er angivet som væsentlige forventede anvendelser kan disse bedømmelser angives således
| Dimension | Målinger og beskrivelser | Bedømmelse |
|---|---|---|
| Aktualitet | Der foretages målinger af de aktuelle forhold hvert 5. minut.
Det publicerede datasæt opdateres hver 6. måned. |
Planlægning af luft- og skibsfart
☆☆☆☆☆ Klimaforskning ★★★★★ |
Evt. yderligere relevant kvalitetsinformation
Deklarationen indeholder desuden et felt til yderligere relevant kvalitetsinformation. Her er der mulighed for at angive anden information der er relevant i forhold til datasættets kvalitet. Det kan være information som falder uden for kernedimensioner, men er vigtige inden for et specifikt domæne (herunder, modtagne certifikater domænespecifikke bedømmelsesskalaer og målinger og beskrivelser der falder uden for kernedimensionerne - fx af præcision) Det kan også være beskrivelse af kvalitetssikringsprocedurer eller af kendte problemstillinger der påvirker datas kvalitet.
Datakvalitetsdimensioner
1. Komplethed
1.1 Definition
Datakvalitetsdimension der indikerer i hvor høj grad datasættet indeholder de dataelementer der er forventede i forhold til datasættets specifikation.
1.2 Beskrivelse
Der er to aspekter af komplethed: Fuldstændighed og dækningsgrad. Et fuldstændigt datasæt indeholder netop én registrering for hvert individ i den population[7](#fodnote 7) datasættet skal beskrive. Når der for hvert individ desuden er registreret alle de forventede/krævede oplysninger om individets egenskaber og relationer til andre individer er det også helt dækkende.
Med andre ord er fuldstændighed altså komplethed i forhold til de eksisterende registreringer og dækningsgrad er komplethed i forhold til de ønskede informationer om registreringerne.
1.3 Relevante målinger og beskrivelser
Fuldstændighed: For nogle datasæt vil det forventede antal af individer være kendt, fx hvis der er tale om kommuner eller regioner. Her er fuldstændigheden simpel at udregne og kan angives som procent af unikke individer der findes i datasættet i forhold til antal individer der burde findes.
For andre er antallet af individer datasættet bør indeholde ukendt og/eller foranderligt, fx i et datasæt om observationer af en truet dyreart i naturen. Her må man lave et fagligt estimat af hvor stor en andel af de observationer der faktisk er foretaget datasættet indeholder, evt. angivet som et interval, fx ’ca. 75-85 % ‘. Desuden bør baggrunden for estimatet, fx sammenligning med andre kilder for antallet, matematiske modeller, stikprøvekontrol, eller feedback fra anvendere, beskrives.
Note: Det er datasættets specifikation der afgør hvad den forventede population er. At der eventuelt eksisterer yderligere data som kunne ønskes inkluderet i datasættet, er ikke relevant hvis specifikationen ikke inkluderer disse.
Dækningsgrad: Dækningsgraden af en egenskab (specifik type af information) angives med procentdelen af registreringer i datasættet der har en værdi registeret for egenskaben, fx hvor mange registreringer der har et bestemt felt udfyldt. Et datasæts dækningsgrad kan angives som et gennemsnit af dækningsgraderne for de krævede egenskaber. Egenskaber som er tydeligt indikeret som valgfri i datasættets specifikation indgår ikke.
Er der betydelig forskel på hvor væsentlige egenskaberne er i forhold til de væsentligste forventede anvendelser kan man vælge at angive dækningsgraden for de væsentligste egenskaber i stedet. Det skal være tydeligt hvilken metode der er valgt, og hvilke egenskaber der er medregnet, hvis det ikke er alle.
Det kan også være relevant at beskrive hvilke informationer der mangler i det omfang man ved det, fx hvis der er brud i en tidsserie, et specifikt geografisk område der mangler registreringer fra eller lignende.
1.4 Eksempler
Et datasæt om kommunale handlingsplaner på socialområdet skal indeholde data om alle kommuner, dvs. om netop 98 kommuner/forekomster. Hvis det kun indeholder 96 kommuner er det ikke fuldstændigt, men har en fuldstændighed på 97,96 %.
Hvis der for hver handlingsplan skal angives en ansvarlig enhed, men dette mangler for 4 ud af 96 handlingsplaner, har datasættet en dækningsgrad på 95,83 % for ’ansvarlig enhed’. Hvis datasættet har dækningsgrader på henholdsvis 100 %, 98,43 %, 99 % og 74,50 % for andre krævede egenskaber, er datasættes gennemsnitlige dækningsgrad gennemsnittet af disse, nemlig 93,55 %.
Noter om bedømmelse
Ud over den konkrete fuldstændighed og dækningsgrad, afhænger bedømmelsen af hvor centrale de manglende informationer er for de forventede anvendelser. Fx er unikker nøgler der kan anvendes til at koble data med data fra andre kilder, så som CVR- og CPR-numre særligt vigtige.
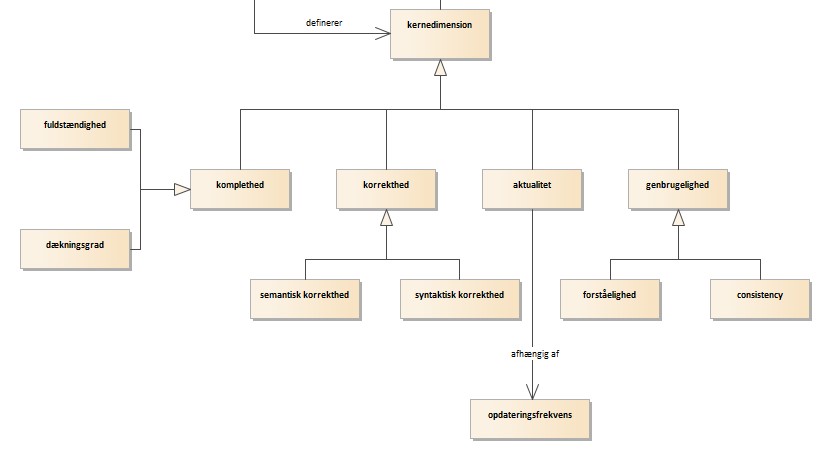
2. Korrekthed
2.1 Definition
Datakvalitetsdimension der indikerer i hvor høj grad dataværdier er i overensstemmelse med faktiske værdier.
2.2 Beskrivelse
Værdier i datasættet skal være sande og korrekt repræsentere den virkelighed datasættet omhandler. Der er to aspekter, henholdsvis semantisk og syntaktisk korrekthed. Semantisk korrekthed betyder at der er overensstemmelse mellem indholdet af de data der er registreret og faktiske forhold (indholdsmæssig korrekthed). Syntaktisk korrekthed betyder at data overholder syntaktiske regler, herunder regler for retstavning samt regler for anvendte strukturerede formater (formmæssig korrekthed).
2.3 Relevante målinger og beskrivelser
Korrekthed angives som andelen af dataværdier der korrekt repræsenterer den faktuelle værdi. I praksis vil det som oftest være umuligt at tjekke korrektheden af alle dataværdier i et datasæt. Derfor vil man som oftest angive et skøn (evt. angivet som interval). Dette skøn kan fx være baseret på stikprøvekontroller, sammenligninger med andre datakilder, oplysninger fra dataleverandører eller hyppighed af fejlrapportering. Grundlaget for skønnet angives.
Desuden kan andre forhold der har relevans for datas korrekthed beskrives kort, herunder om
- data er underlagt valideringsprocedurer, enten inden det optages i datasættet eller løbende
- der er procedurer der sikrer at fejl der opdages under brug rettes
- der er foretaget stavekontrol
- der er anvendt datavask eller andre procedurer der retter/ændrer data
- der – hvis data er angivet i strukturerede formater, herunder xml, html eller rdf - er foretaget validering af at data overholder den/de relevante specifikation(er) (syntaks- og skemavalidering)
2.4 Eksempler
Semantisk korrekthed: En registrering af at en sportsfacilitet som værende en skøjtehal, hvis det i virkeligheden er en svømmehal, eller hvis pågældende svømmehal er registreret som havende handicapvenlige omklædningsfaciliteter uden at sådanne reelt findes, ville være eksempler på semantisk ukorrekthed.
Syntaktisk korrekthed: ’svoemmehal’ følger ikke dansk retstavning og er dermed syntaktisk ukorrekt.
3. Aktualitet
3.1 Definition
Datakvalitetsdimension der indikerer i hvor høj grad data er tidmæssigt aktuelle i forhold til den virkelighed de repræsenterer.
3.2 Beskrivelse
Et datasæt har høj aktualitet, når man (ved brug af nyeste tilgængelige version) kan stole på at det repræsenterer det der faktisk aktuelt er sandt på brugstidspunktet. Aktualitet afhænger af datasættets opdateringsfrekvens i forhold hvor ofte data ændrer sig.
3.3 Relevante målinger og beskrivelser
Nogle datasæt opdateres periodisk med faste intervaller, mens andre opdateres efter behov når der sker ændringer i det som datasættet repræsenterer.
For periodisk opdaterede datasæt angives opdateringsfrekvensen, dvs. hvor lang tid der går mellem opdateringer. Desuden beskrives hvor ofte data typisk ændrer sig. Jo sjældnere data ændrer sig, jo lavere opdateringsfrekvens vil i mange sammenhænge være rimelig samtidig med, at aktualiteten stadig kan anses for at være høj. Dette skal dog ikke en fast regel, da det også skal vurderes i forhold til datas art og hvor kritisk det er for de forventede anvendelser at data er opdaterede.
Hvis datasættet opdateres efter behov, angives hvor lang tid der typisk går fra en ændring sker til denne er blevet registreret og publiceret Man bør opgive tidsrummet så præcist som man kan, men samtidig med den fleksibilitet der er nødvendig. Så 1 time, 3-7 dage, op til 14 dage og ca. 4 måneder er alle acceptable angivelser af tidsrum. Hvis der er forskel på længe der går inden forskellige typer af ændringer registreres/publiceres beskrives dette.
Tidsrummet skal ideelt set angives fra ændringen faktisk sker til den er blevet registreret og publiceret. Der kan dog være situationer, hvor tidsrummet mellem at en ændring sker i den virkelige verden og ændringen observeres eller indmeldes er for variabelt til at dette kan dokumenteres meningsfuldt. I så fald kan tidsrummet beregnes fra informationen modtages og til den er blevet registreret og publiceret. Man skal så angive at det er beregnet på denne måde.
Note: Skulle man have et datasæt bestående af data der ikke ændrer sig (inden for en relevant tidsramme), fx visse geologiske data, angiver man at dette er tilfældet. Aktualiteten af sådanne data vil selvfølgelig kunne bedømmes til 5 stjerner.
3.4 Eksempler
Man kan fx angive at
- der sker ændringer i data flere gange dagligt og den publicerede version af datasættet opdateres en gang i døgnet
- ændringer publiceres inden for en uge fra indrapportering, og at 90% af dataleverandører indrapporterer ugentligt, mens resten kun indrapporterer månedligt
- der oftest går årevis mellem at dataværdier ændrer sig og at datasættet opdateres hver 3. måned
4. Genbrugelighed
4.1 Definition
Datakvalitetsdimension der indikerer i hvor høj grad data er forståelige og uden vanskeligheder kan anvendes af andre.
4.2 Beskrivelse
Denne dimension beskriver de forhold der påvirker hvor egnet et datasæt er til at blive genbrugt til nye formål og har med graden af sammenhæng mellem data og beskrivelsen af disse data at gøre. Det er de forhold der gør at man som menneske kan forstå data samt at en computer kan behandle data.
Genbrugelighedsdimensionen består af to aspekter: Forståelighed og konsistens. Et datasæt har en høj grad af forståelighed når data er ensartet og læsevenligt præsenteret og forsynet med metadata der dokumenterer datas betydning, struktur og oprindelse. Det har en høj grad af konsistens når det overholder dets specifikation/datamodel, er logisk sammenhængende og kan fortolkes utvetydigt.
For datasæt med høj genbrugelighed gælder det derfor at
- data er angivet i forståeligt og entydigt sprog og formater
- der er en tilgængelig datamodel, der
- er forståelig
- indeholder begrebsdefinitioner for alle data
- specificerer anvendte klassifikationer, og for klassifikationer med flere detaljeringsniveauer, hvilket niveau der anvendes
- specificerer anvendte datatyper i forhold til format og anvendte enheder
- hvor relevant, beskrive nøjagtighedsniveau/detaljeringsgrad af de registrerede informationer
- gerne er maskinlæsbar
- datasættet er udarbejdet i overensstemmelse med relevante love og standarder
- der anvendes relevante fælles klassifikationer
- data overholder datasættets datamodel/specifikation
- der er anvendt ensartede og dokumenterede formater for dataværdier
- data overholder relevante forretningsregler og disse er dokumenteret
- datasættet ikke indeholder modstridende informationer
- datasættet indeholder dokumentation af de enkelte dataelementers historik
- der findes dokumentation af datasættets forvaltning
- der er tilstrækkelige metadata der beskriver data
Metadata om datasæt indeholder
- titel på og beskrivelse af datasættet
- oplysninger om datas proveniens (dvs. datas oprindelse og dets vej til optagelse i datasættet)
- oplysninger om seneste opdateringsdato og opdateringsansvarlig
- angivelse af datasættets version og oplysninger om versionshistorik
- oplysninger om fejlretningsprocedure/hvad man gør hvis man opdager fejl
- angivelse af om datasættet overholder relevante love og standarder
- oplysninger om hvorvidt datasættet indeholder personfølsomme eller fortrolige oplysninger
- oplysninger om hvem der er ansvarlig for indsamling af data
- licensoplysninger (hvem må bruge data til hvad)
- kontaktpunkt til at give feedback og stille spørgsmål om datasættet
4.3 Relevante målinger og beskrivelser
Der er en del forskellige forhold der kan påvirke et datasæts genbrugelighed. Nedenfor er angivet en række spørgsmål om disse forhold. Disse spørgsmål er gengivet i skabelonen i bilag A, og man angiver sit svar for hvert spørgsmål.
Spørgsmål om datasættet
Overholder datasættet relevante, ofte domænespecifikke, love og standarder? Hvilke overholder det/ overholder det ikke (endnu)?
Anvender datasættet relevante fælles klassifikationer? Hvilke?
Overholder datasættet relevante forretningsregler? Og er de dokumenteret?
Er datasættets forvaltning dokumenteret?
Spørgsmål om modellering
Er der en tilgængelig datamodel?
Er datamodellen maskinlæselig?
Overholder datasættet datamodellen?
Spørgsmål om metadata
Er datasættet forsynet med alle relevante metadata?
Bilag B indeholder en tjekliste over metadatatyper. Der kan være typer der ikke er relevante for alle datasæt, ligesom der for nogle datatyper/domæner kan være yderligere metadata der er relevante, men bilaget udgør et udgangspunkt for at afgøre om datasættet har de relevante metadata.
Spørgsmål om datatyper
Er datatyper, inkl. udfaldsrum, enheder og præcisionsniveau, hvor relevant, dokumenteret?
Er datatypespecifikationerne overholdt?
Er data af samme type, fx datoer, angivet ensartet?
Spørgsmål om data
Er anvendte dataværdier entydige og forståelige?
Herunder: Er koder og forkortelser forklaret (eller erstattet med forståelig tekst)? Er tekstværdier på dansk (eller evt. andet egnet sprog)? Er det tydeligt om 0/null betyder tallet ’0’, at værdien er ukendt, eller at værdien ikke eksisterer? Er der anvendt standardiserede termer og måleenheder?
Er der referentiel integritet?
Hvis der et sted i datasættet refereres til information et andet sted i datasættet skal denne information eksistere i datasættet. I en relationel database vil det fx sige at fremmednøgler skal pege på poster der indeholder den relevante information.
Indeholder datasættet (hvor relevant) dokumentation af de enkelte dataelementers historik?
Kan man genskabe hvordan et givet dataelement har set ud på et givet tidspunkt og spore hvem der har ændret det? Dette vil ofte gøres ved at dataelementerne har attributterne registreringstid, virkningstid og registreringsaktør. Der kan være typer af dataelementer hvor (alle) disse oplysninger ikke er relevante.
Er datasættet fri for modstridende informationer?
Modstridende informationer kan fx være at referere til den samme entitet på forskellige måder (brug af synonymer eller både fulde navne og forkortelser) eller kan opstå hvis samme oplysning optræder flere steder i datasættet og kan opdateres uafhængigt af hinanden.
4.4 Eksempler
Man kan ikke være sikker på at 10-11-12 betyder den 10. november 2012 med mindre måden datoer angives på er dokumenteret, og alle datoangivelser følger specifikationen.
Hvis nogle værdier af samme type er angivet med en decimal og andre med to kan der opstå tvivl om 34,1 betyder præcis det samme som 34,10 eller der er tale om en afrunding eller en mindre præcis måling.
Hvis navne nogle steder er angivet ’fornavne’ ’efternavn’ og andre steder ’efternavn’, ’fornavne’ kan det besværliggøre databehandling.
Hvis datatypen er angivet til ’integer’ skal en dataværdi angives som 5 ikke ’fem’, og 5 er stadig problematisk hvis udfaldsrummet er angivet til ’1-4’
Lokalt definerede forkortelser, fx forkortelser for afdelingsnavne eller beliggenheder, vil næppe kunne forstås af udenforstående og bør i stedet være skrevet ud eller som minimum forklaret.
Brug af numeriske landekoder gør det væsentligt sværere at læse og forstå data end hvis der er anvendt anerkendte bogstavsforkortelser eller landenavnet er skrevet ud i sin helhed.
Eksempler på relevante forretningsregler kunne være at startdato på et planlagt projekt ikke må være efter slutdato, eller i fortiden, eller at der skal være netop én ansvarlig enhed per projekt.
Hvis betegnelserne ’Erhvervsstyrelsen’ og ’ERST’ bruges i samme datasæt kan der opstå tvivl om hvorvidt der er tale om den samme entitet.
Hvis en persons email er registreret to steder i samme datasæt, og kun opdateret det ene, er der tale om modstridende informationer/inkonsistens.
Noter om bedømmelse
De forskellige aspekter og spørgsmål skal ikke nødvendigvis vægtes lige, men i forhold til hvor vigtige de er for de forventede anvendelser.
For mange datasæt vil det være særligt vigtigt om det overholder de for domænet gældende standarder og benytter gængse klassifikationer på en måde der er sammenlignelig med andre anvendelser. Et andet aspekt der ofte kan være særligt relevant at datasættet indeholder oplysninger om dataelementernes historik.
Ligeledes kan nogle typer af metadata være vigtigere end andre, fx kan udførlige oplysninger om datas proveniens (oprindelse) være særligt vigtigt.
Bilag A: Skabelon til deklaration af datakvalitet
Navn på datasættet:
Det formål datasættet er indsamlet til:
Forventet/forventede anvendelse(r) som datakvalitet er vurderet i forhold til:
Dato for vurdering:
Myndighed eller enhed der er ansvarlig for datakvalitetsvurderingen:
| Dimension | Målinger og beskrivelser
Beskriv datasættets kvalitet i forhold til hver dimension. |
Bedømmelse i forhold til anvendelse
Udfyld det relevante antal stjerner[8](#fodnote 8) |
|---|---|---|
| Komplethed | ☆☆☆☆☆ | |
| Korrekthed | ☆☆☆☆☆ | |
| Aktualitet | ☆☆☆☆☆ | |
| Genbrugelighed | ☆☆☆☆☆ |
Evt. yderligere relevant kvalitetsinformation:
Hjælp til udfyldelse
Det anbefales at læse den samlede vejledning inden udfyldelse af skabelonen. Her gives dog en kortfattet opsummering af vejledning som hjælp til udfyldelsesprocessen.
For hver af de fire kernedimensioner gives først en objektiv beskrivelse af datasættets egenskaber i forhold til dimensionen. Såfremt man har konkrete målinger, resultater af stikprøvekontroller el.lign. bør disse angives. Dernæst udfyldes 0-5 stjerner afhængigt af hvor godt datasættet er i forhold til den eller de væsentligste forventede anvendelse når det gælder den pågældende dimension.
Har man information som falder uden for beskrivelsen af kernedimensionerne, men som man ved er relevante for bedømmelsen af datasættets kvalitet, herunder domænespecifikke oplysninger, beskrivelse af kvalitetssikringsprocedurer eller af kendte problemstillinger der påvirker datas kvalitet, kan disse angives under Evt. yderligere relevant kvalitetsinformation.
Komplethed indikerer i hvor høj grad datasættet indeholder de dataelementer der er forventede i forhold til datasættets specifikation, og har to aspekter: Fuldstændighed er komplethed i forhold til at datasættet indeholder registreringer at de forventede individer (at alle individer – både konkrete og abstrakte ting - er registreret) Dækningsgrad er komplethed i forhold til at datasættet indeholder de forventede oplysninger om de registrerede individers egenskaber (I en relationel database at krævede attributter har værdier)
Det kan hjælpe at overveje følgende spørgsmål:
- Hvor stor en andel af de individer datasættet bør indeholde ifølge dets specifikation er reelt registreret i datasættet? Er dette et skøn?
- Hvor stor en procentdel af de forventede oplysninger om de registrerede individers egenskaber er til stede?
- Dækker denne beregning alle typer af egenskaber eller en specifik delmængde?
- Er der noget at bemærke om dækningsgraden af specifikke egenskaber?
Korrekthed indikerer i hvor høj grad dataværdier er i overensstemmelse med faktiske værdier, og har to aspekter:
Semantisk korrekthed er at der er overensstemmelse mellem indholdet af de data der er registreret og faktiske forhold (indholdsmæssig korrekthed)
Syntaktisk korrekthed er at data overholder syntaktiske regler herunder regler for retstavning og strukturregler (formmæssig korrekthed)
Det kan det hjælpe at overveje følgende spørgsmål:
- Hvor stor en andel af dataværdierne i datasættet kan forventes at repræsentere den faktuelle værdi? Og hvordan er I kommet frem til det tal?
- Valideres data (løbende eller inden optagelse)?
- Er der en fejlretningsprocedure?
- Er der foretaget relevant syntaktisk validering, herunder stavekontrol?
Aktualitet indikerer i hvor høj grad data er tidmæssigt aktuelle i forhold til den virkelighed de repræsenterer (data er ikke forældede)
Det kan det hjælpe at overveje følgende spørgsmål:
- Opdateres datasættet periodisk eller efter behov?
- Hvad er opdateringsfrekvensen? (periodisk)
- Hvor ofte sker der ændringer i det data repræsenterer (ift. opdateringsfrekvens)? (periodisk)
- Hvor længe går der inden ændringer er blevet registreret og publiceret? (efter behov)
Genbrugelighed indikerer i hvor høj grad data er forståelige og uden vanskeligheder kan anvendes af andre, og har to aspekter:
Forståelighed er at data er repræsenteret på en måde der er læselig og forståelig for brugerne (ensartet, læsevenlig, dokumenteret med metadata)
Konsistens er at data er fri for modsigelser og er sammenhængende med andre data (utvetydig fortolkeligt, sammenhæng mellem data i datasættet, sammenhæng med specifikation)
Beskrivelsen af genbrugelighed bør indeholder svar på følgende spørgsmål, som man evt. kan kopiere ind i skabelonen:
- Overholder datasættet relevante love og standarder? Angiv gerne hvilke der overholdes/ikke (endnu) overholdes
- Anvender datasættet relevante fælles klassifikationer? Angiv gerne hvilke
- Er forretningsregler overholdt? Og dokumenteret?
- Er forvaltning af datasættet dokumenteret?
- Er der en tilgængelig datamodel?
- Er datamodellen maskinlæselig?
- Overholder datasættet datamodellen?
- Er datatyper, inkl. range, enheder og præcisionsniveau hvor relevant, dokumenteret?
- Er datasættet forsynet med relevante metadata?
- Er datatypespecifikationerne overholdt?
- Er data af samme type, fx datoer, angivet ensartet?
- Er anvendte dataværdier entydige og forståelige?
- Indeholder datasættet oplysninger om dataelementers historik?
- Er datasættet fri for modstridende informationer?
- Refereres der udelukkende til informationer der faktisk eksisterer
Bedømmelsesskala
| Bedømmelse | Beskrivelse |
|---|---|
| ☆☆☆☆☆ | Bedømmes uegnet til den givne anvendelse |
| ★☆☆☆☆ | Bedømmes til dårligt at kunne anvendes |
| ★★☆☆☆ | Kan anvendes med forbehold for et større antal fejl/utilsigtede resultater |
| ★★★☆☆ | Kan anvendes med forbehold for fejl/utilsigtede resultater |
| ★★★★☆ | Kan anvendes med forbehold for enkelte fejl/utilsigtede resultater |
| ★★★★★ | Kan anvendes umiddelbart og uden forbehold |
Bilag B: Tjekliste til metadata
| Metadatatype | Eventuel kommentar |
|---|---|
| Titel | |
| Identifikator | Entydig persistent identifikation af datasættet. Gerne i form af en http-URI. Kan fx også være en DOI |
| Beskrivelse | |
| Emne/opgave | Henvisning til FORM, KLE eller domænespecifik emneklassifikation. |
| Skaber af datasættet | Organisation eller person der har det primære ansvar for tilvejebringelse af datasættet. |
| Bidragsyder(e) | Andre organisationer eller personer der har ydet væsentlige bidrag til datasættet. |
| Udgiver | Organisation ansvarlig for publiceringen af datasættet. |
| Udgivelsesdato | |
| Senest opdateret | Dato for seneste opdatering |
| Opdateringsansvarlig | Organisation eller person der er ansvarlig for at datasættet bliver opdateret. |
| Version | Se evt. semver.org. |
| Versionsnoter | Beskrivelse af ændringer fra version til version (versionshistorik). |
| Rettighedsangivelse | Hvem har rettighederne til datasættet og under hvilken licens udbydes det? |
| Kontaktpunkt | Kontaktinformation der gør det muligt at give feedback, stille spørgsmål om datasættet og indberette fejl. |
| Proveniensudsagn | Datasættets historik, dvs. hvilke processer det har været genstand for, og hvem der har været ansvarlige for dem. |
| Personoplysningskategori | angivelse af hvorvidt datasættet indeholder ingen personoplysninger, almindelige personoplysninger, følsomme personoplysninger eller oplysninger om strafbare forhold. |
| Fortrolighedsgrad | Oplysning om hvorvidt datasættet indeholder fortrolige oplysninger. |
| Geografisk udstrækning | Relevant hvis data dækker et bestemt geografisk område. |
| Dækningsperiode | Relevant hvis data beskriver en bestemt periode. |
| Standarder | Hvis der er love, direktiver, standarder eller lignende der er relevante for indsamling eller udformning af datasæt er det relevant at angive om datasættet overholder disse. |
| Sprog | Især relevant hvis der er anvendt andre sprog end dansk. |
| Link til hjemmeside | Relevant hvis der findes en hjemmeside med yderlige oplysninger der er relevante for datasættet eller dets brug. |
Bilag C: Eksempel på udfydelse af deklaration af datakvalitet
Datasættets navn: Forekomst af klassisk rabies samt flagermuserabies i vild-og tamdyr i Danmark (Fuldstændigt imaginært datasæt - ikke reelt set i Danmark siden hhv. 1982 og 2009)
Det formål datasættet er indsamlet til: Planlægning af bekæmpelsesindsats
Hvad er den/de væsentligste forventede anvendelser som datakvalitet er vurderet i forhold til: Vurdering af smittefare for landbrugsbesætninger, epidemikontrol
Dato for vurdering: 24 januar 2019
Ansvarlig for datakvalitetsvurderingen: Center for Teknologi og datastrategi, Digitaliseringsstyrelsen
| Dimension | Målinger og beskrivelser
Beskriv datasættets kvalitet i forhold til hver dimension. (Slet gerne hjælpespørgsmålene.) |
Bedømmelse
Udfyld det relevante antal stjerner |
|---|---|---|
| Komplethed | Ved stikprøvekontrol (se nedenfor) var 92% af de forekomster der var registreret hos dyrlægerne også registreret i datasættet.
Alle registrerede forekomster har udfyldt alle attributter, da indtastning uden udfyldelse af alle attributter ikke er mulig. |
★★★★☆ |
| Korrekthed | Ved stikprøvekontrol (se nedenfor) blev der identificeret enkelte stavefejl, primært i navne på anmeldere, men ingen fejl der har betydning for de nævnte anvendelser. | ★★★★★ |
| Aktualitet | Datasættet opdateres halvårligt.
På landsplan ses 1-2 nye tilfælde om måneden. Skulle der opstå epidemi vil dette tal stige væsentligt. |
Smittefarevurdering
★★★★☆ Epidemikontrol ★★☆☆☆ |
| Genbrugelighed | 1. Overholder datasættet relevante love og standarder? Ikke relevant 2. Anvender datasættet relevante fælles klassifikationer? Ja, Veterinærmedicinsk klassifikation 3. Er forretningsregler overholdt? Og dokumenteret? Ved ikke, ikke dokumenteret 4. Er forvaltning af datasættet dokumenteret? Nej 5. Er der en tilgængelig datamodel? Ja 6. Er datamodellen maskinlæselig? Ja 7. Overholder datasættet datamodellen? Ja 8. Er datatyper, inkl. range, enheder og præcisionsniveau hvor relevant, dokumenteret? Udfaldsrum og anvendte enheder er dokumenteret, præcision er ikke relevant 9. Er datasættet forsynet med relevante metadata? Datasættet har kun metadata om emne, opdateringsdato og -ansvarlig og versionering 10. Er datatypespecifikationerne overholdt? Ja 11. Er data af samme type, fx datoer, angivet ensartet? Ja 12. Er anvendte dataværdier entydige og forståelige? Ja 13. Indeholder datasættet oplysninger om dataelementers historik? Nej 14. Er datasættet fri for modstridende informationer? Ja 15. Refereres der udelukkende til informationer der faktisk eksisterer? Ja |
★★★★☆ |
Evt. yderligere relevant kvalitetsinformation:
Stikprøvekontrol af komplethed og korrekthed er foretaget ved at sammenligne data registreret lokalt hos 75 tilfældigt udvalgte dyrlæger med data registreret i datasættet.
Bedømmelsesskala
| Bedømmelse | Beskrivelse |
|---|---|
| ☆☆☆☆☆ | Bedømmes uegnet til den givne anvendelse |
| ★☆☆☆☆ | Bedømmes til dårligt at kunne anvendes |
| ★★☆☆☆ | Kan anvendes med forbehold for et større antal fejl/utilsigtede resultater |
| ★★★☆☆ | Kan anvendes med forbehold for fejl/utilsigtede resultater |
| ★★★★☆ | Kan anvendes med forbehold for enkelte fejl/utilsigtede resultater |
| ★★★★★ | Kan anvendes umiddelbart og uden forbehold |
Bilag D: Dimensioner fra internationale standarder
Herunder kan den interesserede læser se de fulde dimensionssæt fra de internationale standarder, der har været den primære inspiration for kernedimensionerne. Kernedimensionerne er nedenfor mappet til de to dimensionssæt.
Har man information om / målinger af datakvaliteten af sit datasæt for en dimension fra en af de internationale standarder kan man evt. beskrive det i deklarationen under punktet Evt. yderligere relevant kvalitetsinformation.
Fuldt dimensionssæt fra ISO 25012
(ISO 25012 – Software engineering – Software product Quality Requirements and Evaluation (SQuaRE) – Data quality model)
| Dimension | Definition |
|---|---|
| Accuracy | The degree to which data has attributes that correctly represent the true value of the intended attribute of a concept or event in a specific context of use. |
| Completeness | The degree to which subject data associated with an entity has values for all expected attributes and related entity instances in a specific context of use. |
| Consistency | The degree to which data has attributes that are free from contradiction and are coherent with other data in a specific context of use. It can be either or both among data regarding one entity and across similar data for comparable entities. |
| Credibility | The degree to which data has attributes that are regarded as true and believable by users in a specific context of use. Credibility includes the concept of authenticity (the truthfulness of origins, attributions, commitments). |
| Currentness | The degree to which data has attributes that are of the right age in a specific context of use. |
| Accessibility | The degree to which data can be accessed in a specific context of use, particularly by people who need supporting technology or special configuration because of some disability. |
| Compliance | The degree to which data has attributes that adhere to standards, conventions or regulations in force and similar rules relating to data quality in a specific context of use. |
| Confidentiality | The degree to which data has attributes that ensure that it is only accessible and interpretable by authorized users in a specific context of use. Confidentiality is an aspect of information security (together with availability, integrity) as defined in ISO/IEC 13335-1:2004. |
| Efficiency | The degree to which data has attributes that can be processed and provide the expected levels of performance by using the appropriate amounts and types of resources in a specific context of use. |
| Precision | The degree to which data has attributes that are exact or that provide discrimination in a specific context of use. |
| Traceability | The degree to which data has attributes that provide an audit trail of access to the data and of any changes made to the data in a specific context of use. |
| Understandability | The degree to which data has attributes that enable it to be read and interpreted by users, and are expressed in appropriate languages, symbols and units in a specific context of use. Some information about data understandability are provided by metadata. |
| Availability | The degree to which data has attributes that enable it to be retrieved by authorized users and/or applications in a specific context of use. |
| Portability | The degree to which data has attributes that enable it to be installed, replaced or moved from one system to another preserving the existing quality in a specific context of use. |
| Recoverability | The degree to which data has attributes that enable it to maintain and preserve a specified level of operations and quality, even in the event of failure, in a specific context of use. |
Fuldt dimensionssæt fra Linked Data Quality Dimensions-vokabularet
(http://www.w3.org/2016/05/ldqd, udarbejdet på baggrund af Amrapali Zaveri, Anisa Rula, Andrea Maurino, Ricardo Pietrobon, Jens Lehmann, Sören Auer: Quality assessment for Linked Data: A Survey. Semantic Web 7(1): 63-93 (2016) https://dx.doi.org/10.3233/SW-150175)
| Dimension | Definition |
|---|---|
| Availability | Availability of a dataset is the extent to which data (or some portion of it) is present, obtainable and ready for use. |
| Licensing | Licensing is defined as the granting of permission for a consumer to re-use a dataset under defined conditions. |
| Interlinking | Interlinking refers to the degree to which entities that represent the same concept are linked to each other, be it within or between two or more data sources. |
| Security | Security is the extent to which data is protected against alteration and misuse. |
| Performance | Performance refers to the efficiency of a system that binds to a large dataset, that is, the more performant a data source is the more efficiently a system can process data. |
| Syntactic validity | Syntactic validity is defined as the degree to which an RDF document conforms to the specification of the serialization format. |
| Semantic accuracy | Semantic accuracy is defined as the degree to which data values correctly represent the real world facts. |
| Consistency | Consistency means that a knowledge base is free of (logical/formal) contradictions with respect to particular knowledge representation and inference mechanisms. |
| Conciseness | Conciseness refers to the minimization of redundancy of entities at the schema and the data level. |
| Completeness | Completeness refers to the degree to which all required information is present in a particular dataset. |
| Relevancy | Relevancy refers to the provision of information which is in accordance with the task at hand and important to the users’ query. |
| Trustworthiness | Trustworthiness is defined as the degree to which the information is accepted to be correct, true, real and credible. |
| Understandability | Understandability refers to the ease with which data can be comprehended without ambiguity and be used by a human information consumer. |
| Timeliness | Timeliness measures how up-to-date data is relative to a specific task. |
| Representational-conciseness | Representational-conciseness refers to the representation of the data, which is compact and well formatted. |
| Interoperability | Interoperability is the degree to which the format and structure of the information conforms to previously returned information as well as data from other sources. |
| Interpretability | Interpretability refers to technical aspects of the data, that is, whether information is represented using an appropriate notation and whether the machine is able to process the data. |
| Versatility | Versatility refers to the availability of the data in different representations and in an internationalized way. |
Mapning mellem kernedimensioner og internationale standarder
Mapning til ISO 25012
| Kernedimension | ISO 25012-dimension | Mapningsrelation |
|---|---|---|
| Komplethed | Completeness
The degree to which subject data associated with an entity has values for all expected attributes and related entity instances in a specific context of use. |
Completeness er et underbegreb til Komplethed
(skos:narrowMatch) Note: ISO-dimension indeholder kun aspektet dækningsgrad |
| Korrekthed | Accuracy
The degree to which data has attributes that correctly represent the true value of the intended attribute of a concept or event in a specific context of use |
Fuld ækvivalens (skos:exactMatch) |
| Aktualitet | Currentness
The degree to which data has attributes that are free from contradiction and are coherent with other data in a specific context of use. It can be either or both among data regarding one entity and across similar data for comparable entities |
Fuld ækvivalens (skos:exactMatch) |
| Genbrugelighed | Consistency
The degree to which data has attributes that are free from contradiction and are coherent with other data in a specific context of use. It can be either or both among data regarding one entity and across similar data for comparable entities |
Consistency er et underbegreb til Genbrugelighed
(skos:narrowMatch) |
| Understandability
The degree to which data has attributes that enable it to be read and interpreted by users, and are expressed in appropriate languages, symbols and units in a specific context of use. Some information about data understandability are provided by metadata |
Understandability er et underbegreb til Genbrugelighed
(skos:narrowMatch) |
Mapning til Linked Data Quality Dimensions
| Kernedimension | Linked Data Quality Dimension | Mapningsrelation |
|---|---|---|
| Komplethed | Completeness
Completeness refers to the degree to which all required information is present in a particular dataset |
Fuld ækvivalens (skos:exactMatch) |
| Korrekthed | Semantic Accuracy
Semantic accuracy is defined as the degree to which data values correctly represent the real world facts |
Semantic Accuracy er et underbegreb til korrekthed (skos:narrowMatch)
Note: ldqd-dimension har fuld ækvivalens med aspektet semantisk korrekthed |
| Aktualitet | Timeliness
Timeliness measures how up-to-date data is relative to a specific task |
Fuld ækvivalens (skos:exactMatch) |
| Genbrugelighed | Consistency
Consistency means that a knowledge base is free of (logical/formal) contradictions with respect to particular knowledge representation and inference mechanisms |
Consistency er et underbegreb til Genbrugelighed
(skos:narrowMatch) |
| Understandability
Understandability refers to the ease with which data can be comprehended without ambiguity and be used by a human information consumer |
Understandability er et underbegreb til Genbrugelighed
(skos:narrowMatch) |
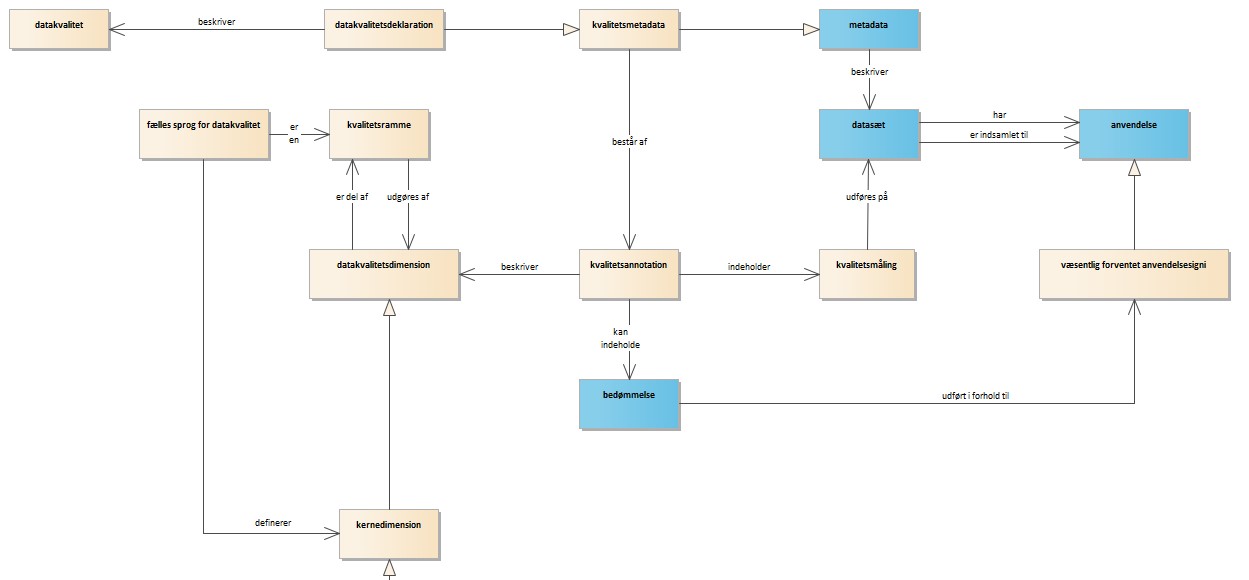
Bilag E: Begreber
I dette bilag findes en begrebsliste, hvor de mest centrale begreber i forbindelse med denne vejledning defineres, samt et begrebsdiagram der illustrerer sammenhængen mellem begreberne. Begrebsmodellen findes også her: https://data.gov.dk/modelgroup/datakvalitet/
Begrebsliste
| Foretrukken dansk term | Accepteret dansk term | Frarådet dansk term | Definition | Eksempel | Kommentar | Juridisk kilde | Kilde | Tilhører emne-område |
|---|---|---|---|---|---|---|---|---|
| aktualitet | tidstrohed | datakvalitetsdimension der indikerer i hvor høj grad data er tidsmæssigt aktuelle i forhold til den virkelighed de repræsenterer | Projektet Fælles sprog for datakvalitet, Den fællesoffentlige digitaliseringsstrategi 2016-2020 | Ja | ||||
| anvendelse | en beskrivelse af handlinger og formål et datasæt eller datasætdistribution kan anvendes til | http://www.w3.org/TR/vocab-duv/ | Nej | |||||
| bedømmelse | vurdering | evaluering på en numerisk skala | https://schema.org/Rating | Nej | ||||
| datakvalitet | grad af tilfredsstillelse af udtrykte og underforståede behov datas egenskaber giver ved brug under specifikke omstændigheder | ISO 25012 Data Quality Model | Ja | |||||
| datakvalitets-deklaration | dokument der angiver oplysninger om datakvaliteten i et givet datasæt | Projektet Fælles sprog for datakvalitet, Den fællesoffentlige digitaliseringsstrategi 2016-2020 | Ja | |||||
| datakvalitetsdimension | kvalitetsdimension | kriterier der er relevante for at vurdere kvalitet | https://www.w3.org/TR/vocab-dqv | Ja | ||||
| datasæt | datasamling | en samling af data, udstillet eller forvaltet af en enkelt aktør | https://www.w3.org/TR/vocab-dcat-2/ | Nej | ||||
| dækningsgrad | attribut-komplethed | komplethed i forhold til at datasættet indeholder de forventede oplysninger om de registrerede individers egenskaber | Projektet Fælles sprog for datakvalitet, Den fællesoffentlige digitaliseringsstrategi 2016-2020 | Ja | ||||
| forståelighed | indikation af i hvor høj grad data er repræsenteret på en måde der er læselig og forståelig for brugerne | ISO 25012 Data Quality Model | Ja | |||||
| fuldstændighed | komplethed i forhold til at datasættet indeholder registreringer af de forventede individer | Projektet Fælles sprog for datakvalitet, Den fællesoffentlige digitaliseringsstrategi 2016-2020 | Ja | |||||
| fælles sprog for datakvalitet | fællesoffentlig kvalitetsramme der definerer kernedimensioner | Projektet Fælles sprog for datakvalitet, Den fællesoffentlige digitaliseringsstrategi 2016-2020 | Ja | |||||
| genbrugelighed | datakvalitetsdimension der indikerer i hvor høj grad data er forståelige og uden vanskeligheder kan anvendes af andre | Projektet Fælles sprog for datakvalitet, Den fællesoffentlige digitaliseringsstrategi 2016-2020 | Ja | |||||
| kernedimension | datakvalitetsdimension, der anses for central i forbindelse med opmærkning af datasæt med kvalitetsinformation i dansk fællesoffentlig kontekst | Projektet Fælles sprog for datakvalitet, Den fællesoffentlige digitaliseringsstrategi 2016-2020 | Ja | |||||
| komplethed | datakvalitetsdimension der indikerer i hvor høj grad datasættet indeholder de dataelementer der er forventede i forhold til datasættets specifikation | Projektet Fælles sprog for datakvalitet, Den fællesoffentlige digitaliseringsstrategi 2016-2020 | Ja | |||||
| konsistens | indikation af i hvor høj grad data er fri for modsigelser og er sammenhængende med andre data | ISO 250012 Data Quality Model | Ja | |||||
| korrekthed | datakvalitetsdimension der indikerer i hvor høj grad dataværdier er i overensstemmelse med faktiske værdier | Projektet Fælles sprog for datakvalitet, Den fællesoffentlige digitaliseringsstrategi 2016-2020 | Ja | |||||
| kvalitets-annotation | annotationer om kvalitet, inklusiv vurderinger, kvalitetscertifikater eller feedback, der kan associeres til datasæt eller deres distributioner | https://www.w3.org/TR/vocab-dqv | Ja | |||||
| kvalitetsmetadata | metadata der omhandler kvalitet | http://www.w3.org/ns/dqv | Ja | |||||
| kvalitetsmåling | evaluering af et givent datasæt (eller datasætdistribution) i forhold til en specifik metode | https://www.w3.org/TR/vocab-dqv | Ja | |||||
| kvalitetsramme | kvalitets-rammeværk | et antal kvalitetsdimensioner der er udarbejdet med henblik på at udgøre en ramme for kvalitetsbeskrivelse | Projektet Fælles sprog for datakvalitet, Den fællesoffentlige digitaliseringsstrategi 2016-2020 | Ja | ||||
| metadata | data der giver information om andre data | https://www.merriam-webster.com/dictionary/metadata | Nej | |||||
| opdateringsfrekvens | hvor ofte noget opdateres | Projektet Fælles sprog for datakvalitet, Den fællesoffentlige digitaliseringsstrategi 2016-2020 | Ja | |||||
| semantisk korrekthed | indholdsmæssig korrekthed | korrekthed i form af overensstemmelse mellem indholdet af de data der er registreret og faktiske forhold | Projektet Fælles sprog for datakvalitet, Den fællesoffentlige digitaliseringsstrategi 2016-2020 | Ja | ||||
| syntaktisk korrekthed | formmæssig korrekthed | korrekthed i form af at data overholder syntaktiske regler herunder regler for retstavning og strukturregler for anvendte formater | Projektet Fælles sprog for datakvalitet, Den fællesoffentlige digitaliseringsstrategi 2016-2020 | Ja | ||||
| væsentlig forventet anvendelse | anvendelse som der er et betydeligt potentiale i at begynde eller forsætte med at anvende datasættet til | Projektet Fælles sprog for datakvalitet, Den fællesoffentlige digitaliseringsstrategi 2016-2020 | Ja |
Begrebsdiagram
Del 1
Del 2
Bilag F: Datamodel
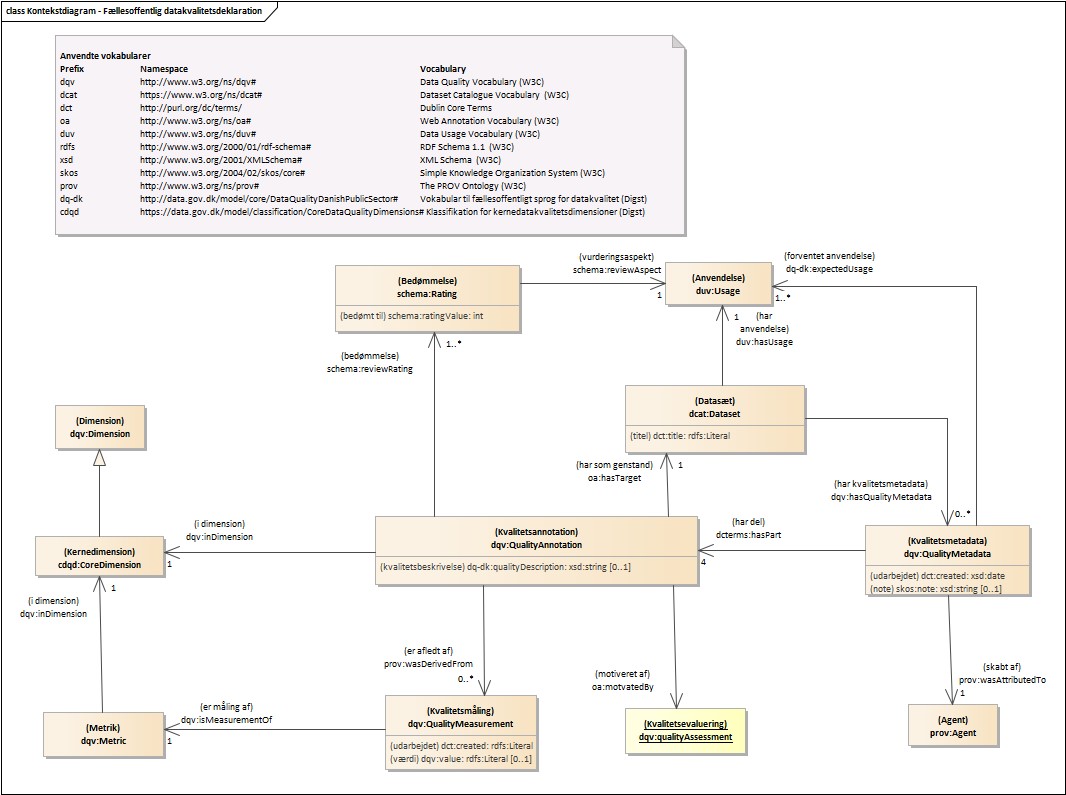
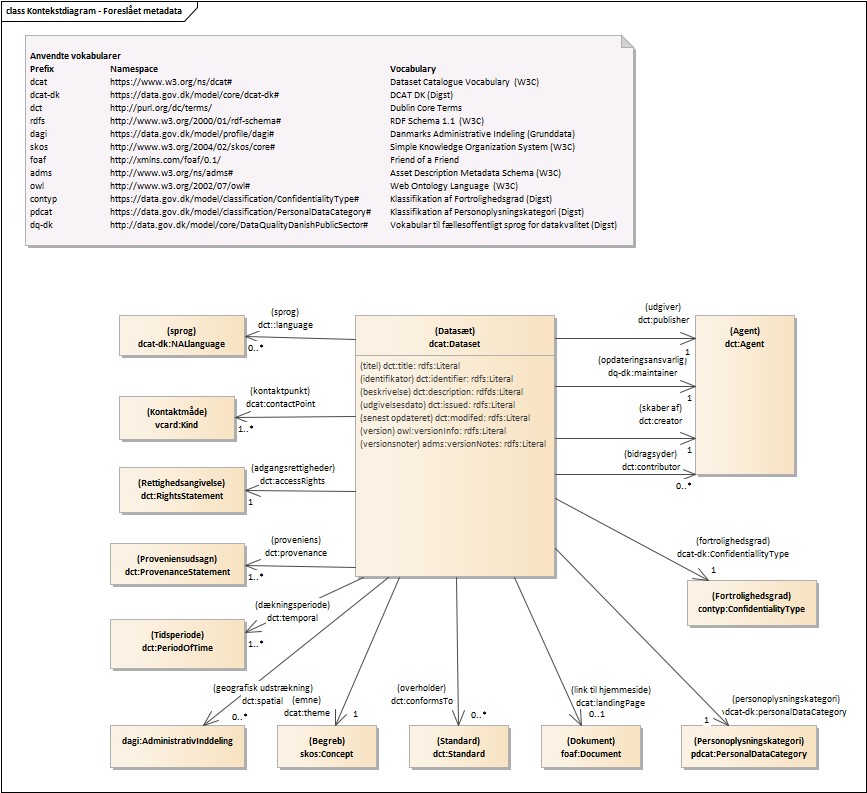
Den fulde anvendelsesprofil og vokabular udarbejdet i forbindelse med fælles sprog for datakvalitet kan findes på https://data.gov.dk/modelgroup/datakvalitet/.
Nedenfor ses kontekstdiagrammer for datakvalitetsdeklarationen og de foreslåede metadata.
Datakvalitetsdeklaration
Foreslåede metadata
Fodnoter
1 https://www.w3.org/TR/vocab-dqv
2 ISO 25012:2008 Software engineering – Software product Quality Requirements and Evaluation (SQuaRE) – Data quality model
3 Oversat fra ”degree to which the characteristics of data satisfy stated and implied needs when used under specified conditions”
4 Tilpasset fra definition af datasæt i W3C anbefalingen Data Catalog Vocabulary (https://www.w3.org/TR/vocab-dcat/): “A collection of data, published or curated by a single source, and available for access or download in one or more formats”
5 Mapning mellem kernedimensionerne og ISO 25012 /Linked Data Quality Dimensions findes I bilag D
6 Det kan dog anbefales at give anvendere mulighed for at give feedback om deres oplevelse af datakvaliteten, jævnfør W3C anbefaling Data on the Web Best Practices (31-01-2017) – Best Practice 29
7 I denne sammenhæng skal individ forstås som en konkret eller abstrakt ting der skal registreres i datasættet. Det kan være et individ i ordets traditionelle forstand men også en organisation, en genstand, en oplysning, en begivenhed, en observation mm. Population er den gruppe af individer man gerne vil registrere information om.
8 Marker det ønskede antal stjerner og vælg en farve under ’Udfyldning’ (malerspandsikonet)